
Si dans un téléphone, on écoute les sons qu’émettent un Minitel, un fax ou un micro-ordinateur pour échanger des données, ils se présentent à nous comme un sifflement suraigu bourré de parasites : le message semble parfaitement inintelligible. A l’inverse, alors que notre propre langage nous paraît simple et clair, la machine, elle, n’y détecte rien de cohérent.
L’utilisation de la parole comme mode de communication entre un homme et une machine a été largement étudiée au cours des dernières années. C’est depuis, en fait, 1945 que les chercheurs commencèrent à s’intéresser à la » conversation entre un homme et une machine « . Mais comment une machine pourrait-elle se munir d’une » oreille » ? Par quel dispositif peut-on réaliser cette communication homme-machine ? Comment la machine traite-elle les informations qu’elle reçoit ? En quoi cela peut-t-il servir ?
Pour répondre à cela, nous allons tout d’abord faire un historique du sujet, faire l’analyse du signal de parole, puis traiter les différentes méthodes employées pour réaliser un système de reconnaissance vocale, et enfin donner quelques applications si petites seront-elles.
HISTOIRE RACONTE
La reconnaissance de la parole est une discipline récente. Vers 1950 apparut le premier système de reconnaissance de chiffres, appareil entièrement câblé et très imparfait. Vers 1960, l’introduction des méthodes numériques et l’utilisation des ordinateurs changent la dimension des recherches. Néanmoins, les résultats demeurent modestes car la difficulté du problème avait été largement sous-estimée, en particulier en ce qui concerne la parole continue. Vers 1970, la nécessité de faire appel à des contraintes linguistiques dans le décodage automatique de la parole avait été jusque-là considérée comme un problème d’ingénierie. La fin de la décennie 70 voit se terminer la première génération des systèmes commercialisés de reconnaissance de mots. Les générations suivantes, mettant à profit les possibilités sans cesse croissantes de la micro-informatique, posséderont des performances supérieures (systèmes multilocuteurs , parole continue).
On peut résumer en quelques dates les grandes étapes de la reconnaissance de la parole (cf Techniques de l’ingénieur, vol.H1 940, p.3) :
– 1952 : reconnaissance 10 chiffres, pour un monolocuteur , par un dispositif électronique câblé
– 1960 : utilisation des méthodes numériques
– 1965 : reconnaissance de phonèmes en parole continue
– 1968 : reconnaissance mots isolés par systèmes implantés sur gros ordinateurs (à 500 mots)
– 1969 : utilisation d’informations linguistiques
– 1971 : lancement du projet ARPA aux USA (15 millions de dollars) pour tester la faisabilité de la compréhension automatique de la parole continue avec des contraintes raisonnables
– 1972 : premier appareil commercialisé de reconnaissance de mots
– 1976 : fin du projet ARPA ; les systèmes opérationnels sont HARPY, HEARSAY I et II et HWIM
– 1978 : commercialisation dun système de reconnaissance à microprocesseurs sur une carte de circuits imprimés
– 1981 : utilisation de circuits intégrés VLSI (Very Large Scale Integration) spécifiques du traitement de la parole
– 1981 : système de reconnaissance de mots sur un circuit VLSI
– 1983 : première mondiale de commande vocale à bord d’un avion de chasse en France
– 1985 : commercialisation des premiers systèmes de reconnaissance de plusieurs milliers de mots
– 1986 : lancement du projet japonais ATR de téléphone avec traduction automatique en temps réel
– 1988 : apparition des premières machines à dicter par mots isolés
– 1989 : recrudescence des modèles connexionnistes neuromimétiques
– 1990 : premières véritables applications de dialogue oral homme-machine
– 1994 : IBM lance son premier système de reconnaissance vocale sur PC
– 1997 : lancement de la dictée vocale en continu par IBM
1971, année charnière pour la recherche comme le feu dans le silex
La plupart des informations suivantes sont tirées de » Synthèse, reconnaissance de la parole » (Marc Ferretti et François Cinare).
En 1951, S.P. Smith présente un détecteur de phonèmes ; une année après, K.H. Davis, R Biddulph et S.Baleshek annoncent la première machine à aborder la reconnaissance de manière globale : les dix chiffres « zero » à « nine » sont reconnus analogiquement avec un bon taux de réussite pour une seule voix. En 1960, P.B. Denes et M.V. Matthews, pour reconnaître les dix premiers chiffres, comparent globalement les représentations temps fréquence, numérisées et normalisées en durée totale : le taux d’erreur est nul pour un seul locuteur et s’élève à 6% pour cinq locuteurs ayant participé à un apprentissage.
H.F. Olson et H.Belar envisagent, en 1961, la reconnaissance d’unités phonétiques autres que les phonèmes : leurs unités sont des « syllabes phonétiques » que le locuteur doit articuler séparément ou, du moins, avec une chute importante du niveau sonore en guise de séparation ; il s’agit donc presque d’une reconnaissance par mots, étant entendu que ces « mots » sont courts et que leur répertoire est limité : 2000 syllabes suffisent à couvrir 98% des besoins de la langue anglaise.
J.Dreyfus-Graf met au point en 1961 son « phonétographe », appareillage analogique composé de vingt filtres passe-bande et de circuits identificateurs de phonèmes. Le phonétographe utilise des « compresseurs sélectifs » qui augmentent l’émergence de certains phonèmes ; obtenu en temps réel, le résultat est spectaculaire ; cependant, l’appareil ne fonctionne qu’avec un seul locuteur qui doit adapter sa diction à la machine : hauteur, intensité, rythme très faibles.
Après avoir constaté que l’identification des phonèmes dans le signal de parole est un problème beaucoup plus compliqué qu’ils ne l’imaginaient, les chercheurs se tournent, entre 1965 et 1970, d’une part vers la reconnaissance par mots isolés en vue d’applications pratiques comme la commande vocale, d’autre part vers l’utilisation d’informations de niveau linguistique supérieur avec lexique et syntaxe , pour compléter le message vocal reconnu au niveau phonétique. Cette seconde approche prend le nom, quelque peu abusif, de « compréhension automatique de la parole ».
1971 est une année charnière à double titre. D’abord, elle voit la première réalisation commerciale en reconnaissance vocale : « le Voice Command system » de J.J.W. Glenn et M.H. Hitchcok, appareil autonome qui reconnaît de manière fiable 24 mots isolés après cinq cycles d’apprentissage par le même locuteur. L’analyse du message est effectuée par un banc de seize filtres ; chaque mot est représenté par huit événements prélevés aux instants de plus grande variation interne du message. Cette normalisation temporelle, ainsi que les traitements d’apprentissage et de reconnaissance, sont confiés à un mini calculateur incorporé.
Aux Etats-Unis, l’importance des recherches sur la parole a beaucoup varié au cours des dernières années. A l’effort de recherche particulièrement intensif correspondant au projet SUR (Speech Understanding Research) de l’Arpa (Advanced Research Projects Agency), succède maintenant un effort plus mesuré. Les systèmes mis alors au point font aujourd’hui l’objet de recherches limitées (BBN), sont développés en vue d’applications industrielles (Harpy), ont été commercialisés (VIP 100) ou ont été abandonnés (Dragon).
En ex-URSS, les recherches dans ce domaine ont commencé très tôt et restent à l’heure actuelle très actives. Mais à la différence des équipes américaines qui ont développé rapidement d’énormes systèmes de compréhension de la parole, les équipes soviétiques n’ont que très récemment abordé l’étude des niveaux syntaxique et sémantique ; elles sont à l’origine de l’utilisation de la technique de « programmation dynamique » dont l’emploi s’est maintenant partout généralisé.
En France, les recherches ont démarré vers 1970, et plusieurs laboratoires de recherches ont pu mettre au point différents systèmes de reconnaissance vocale avec plus ou moins de succès, ces laboratoires mettant l’accent sur le support de reconnaissance : mots isolés, syllabes, grands vocabulaires.
D’aucuns peuvent dire qu’importe peu de savoir comment cela fonctionne mais, comme toute littérature, à défaut de mourir ignorant, il est bon de s’informer et s’informer, c’est sortir d’un illettrisme du domaine du sujet alors :
Analyse du signal de parole et décodage
Une fois que le son a été émis par le locuteur, il est capté par un microphone. Le signal vocal est ensuite numérisé à l’aide d’un convertisseur analogique-numérique. Comme la voix humaine est constituée d’une multitude de sons, souvent répétitifs, le signal peut être compressé pour réduire le temps de traitement et l’encombrement en mémoire. L’analyse peut alors commencer.
La Paramétrisation
La première étape consiste à paramétrer le signal vocal du locuteur. Cela permet d’obtenir une » empreinte » caractéristique du son, sur laquelle on pourra ensuite travailler pour la reconnaissance. Pour cela, il existe plusieurs méthodes (cf les Techniques de l’ingénieur vol. H1 940 p. 4 et 5 ; MacGraw-Hill encyclopedia cote 603 / ANG McG (XVII) p. 233, 234 ; » Reconnaissance automatique de la parole » (J.-P.Haton, J.-M.Pierrel, G.Perennou, J.Caelen, J.-L.Gauvain) p.26 à 32 ; Science et Vie Micro n°128 p.222).
Un premier groupe de méthodes est constitué par les méthodes spectrales . Elles sont fondées sur la décomposition fréquentielle du signal sans connaissance a priori de sa structure fine. La plus utilisée est celle utilisant la transformée de Fourier, appelée Fast Fourier Transform ( FFT ). Tout son est la superposition de plusieurs ondes sinusoïdales. Grâce à la FFT , on peut isoler les différentes fréquences qui les composent. On obtient ainsi une répartition spectrale du signal.
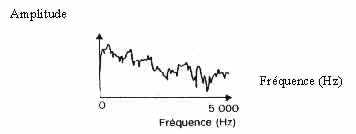
Spectre obtenu par transformée rapide de Fourier (FFT)
(doc INSA, Techniques de l’ingénieur, traité pratique informatique, vol. H1 940)
En appliquant la FFT à un son complexe et en la répétant de nombreuses fois, on dresse un graphique donnant l’évolution de l’amplitude et de la fréquence en fonction du temps. On obtient ainsi une empreinte caractéristique du son.
Un deuxième groupe de méthodes est constitué par les méthodes d’identification. Elles sont fondées sur une connaissance des mécanismes de production (ex : le conduit vocal). La plus utilisée est celle basée sur le codage prédictif linéaire (appelée LPC ). L’hypothèse de base est que le canal buccal est constitué d’un tube cylindrique de section variable. L’ajustement des paramètres de ce modèle permet de déterminer à tout instant sa fonction de transfert. Cette dernière fournit une approximation de l’enveloppe du spectre du signal à l’instant d’analyse.
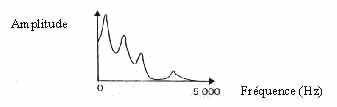
Spectre lissé obtenu par prédiction linéaire (LPC)
(doc INSA, Techniques de l’ingénieur, traité pratique informatique, volume H1 940, p.5)
On repère alors aisément les fréquences formantiques , c’est-à-dire les fréquences de résonance du conduit vocal. En effet, elles correspondent au maximum d’énergie dans le spectre. En répétant cette méthode plusieurs fois, on obtient l’empreinte du signal, comme le montre la figure ci-après.
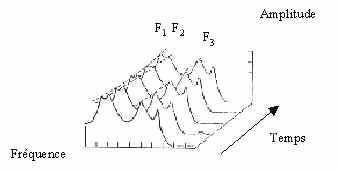
Empreinte obtenue par prédiction linéaire (LPC).
(doc INSA, MacGraw-Hill encyclopedia, cote 603 / ANG McG (XVII), p.233)
D’autres méthodes existent, mais elles sont moins employées et nous ne les détaillerons pas ici (cf » Reconnaissance automatique de la parole » cote Part-Dieu 006.454 REC p.27, 28, 33). Les tendances actuelles visent à améliorer l’analyse fine des sons : codage impulsionnel, analyse fractal. Le codage vectoriel permet de diminuer la quantité d’informations nécessaires pour coder un mot (et donc l’espace mémoire), en s’appuyant sur un dictionnaire de spectres instantanés (cf les Techniques de l’ingénieur vol. H1 940 p.5).
D’autre part, l’information prosodique est dominée par la variation de la fréquence du fondamental Fo . Il est donc important de la déterminer (cf » Reconnaissance automatique de la parole » cote Part-Dieu 006.454 REC p.34 à 36). Pour cela, il existe des méthodes temporelles et fréquentielles utilisant des filtres et le spectre du signal. Certains problèmes se posent : l’excitation glottale n’est pas rigoureusement périodique ; la source peut être atténuée dans certains types de transmissions (téléphone), etc.. Il est par conséquent difficile d’effectuer des mesures précises.
Une fois que l’on a obtenu l’empreinte caractéristique du signal, on peut passer à l’étape suivante, qui est le décodage acoustico-phonétique :
Décodage acoustico-phonétique
Il consiste à décrire le signal acoustique de parole en termes d’unités linguistiques discrètes (cf » Reconnaissance automatique de la parole » cote Part-Dieu 006.454 REC p.11, 12, 40 à 55) ; Techniques de l’ingénieur vol. H1 940 p.8). Les unités les plus utilisées sont les phonèmes , les syllabes, les mots. Un phonème est un élément sonore d’un langage donné, déterminé par les rapports qu’il entretient avec les autres sons de ce langage. Par exemple, le mot » cou » est formé des phonèmes » keu » et » ou « . Il en existe une trentaine en français.
Cette notion est assez importante en reconnaissance vocale.
Le décodage a pour but de segmenter le signal en segments élémentaires et d’étiqueter ces segments. Le principal problème est de choisir les unités sur lesquelles portera le décodage. Si des unités longues telles que les syllabes ou les mots sont choisies, la reconnaissance en elle-même sera facilitée mais leur identification est difficile. Si des unités courtes sont choisies, comme les phones (sons élémentaires), la localisation sera plus facile mais leur exploitation nécessitera de les assembler en unités plus larges. Les phonèmes constituent un bon compromis, leur nombre est limité : ils sont donc souvent utilisés. Mais le choix dépend également du type de reconnaissance effectuée : mots isolés ou parole continue.
Une fois la segmentation effectuée, l’identification des différents segments se fait en fonction de contraintes phonétiques, linguistiques. Il faut que le système ait intégré un certain nombre de connaissances : données articulatoires, sons du français, données phonétiques, prosodiques , syntaxiques , sémantiques !
Deux sortes d’outils sont utilisées : les outils de reconnaissance de formes structurelle (RFS, ex : grammaires déterministes) et les outils provenant de systèmes experts. Ils sont souvent associés pour de meilleures performances. Un système expert effectue les interprétations et déductions nécessaires grâce à la modélisation préalable du raisonnement de l’expert (domaine de l’intelligence artificielle).
Une fois que tout cela a été effectué, la reconnaissance en elle-même peut commencer, que ce soit pour des mots isolés ou pour de la parole continue.
Reconnaissance de mots isolés
L’absence dans le signal vocal d’indicateurs sur les frontières de phonèmes et de mots constitue une difficulté majeure de la reconnaissance de la parole. De ce fait, la reconnaissance de mots prononcés artificiellement de façon isolée (c’est à dire que tous les mots prononcés sont séparés par des silences de durées supérieures à quelques dixièmes de seconde) représente une simplification notable du problème.
Deux systèmes ont cours actuellement :
Le système monolocuteur (utilisable par un seul locuteur) est caractérisé par la technique d’apprentissage, où une seule et même personne doit dicter un ensemble de mots, ce qui permet d’optimiser le taux de reconnaissance et d’étendre le vocabulaire utilisable. Inconvénient, seule la personne ayant fourni son empreinte vocale (lors de la phase d’apprentissage) peut travailler.
Le système multilocuteur (utilisable par plusieurs locuteurs) qui utilise une base de données contenant des empreintes moyennes autorisant la reconnaissance de plusieurs voix. Inconvénient, le système n’est pas doté de capacités d’apprentissage et le nombre de mots est plus limité.
Toutes ces informations sont tirées de : Techniques de l’ingénieur vol. H1 940 ; » Reconnaissance automatique de la parole » cote Part-Dieu 006.454 REC ; Science et Vie Micro n°128.
* Les techniques de reconnaissance vocale
Deux approches, l’une plus globale, l’autre plus analytique permettent d’appréhender la reconnaissance des mots. Dans l’approche globale , l’unité de base sera le plus souvent le mot considéré comme une entité globale, c’est à dire non décomposée. L’idée de cette méthode est de donner au système une image acoustique de chacun des mots qu’il devra identifier par la suite. Cette opération est faite lors de la phase d’apprentissage, où chacun des mots est prononcé une ou plusieurs fois. Cette méthode a pour avantage d’éviter les effets de coarticulation, c’est à dire l’influence réciproque des sons à l’intérieur des mots. Elle est cependant limitée aux petits vocabulaires prononcés par un nombre restreint de locuteurs.
L’approche analytique , qui tire parti de la structure linguistique des mots, tente de détecter et d’identifier les composantes élémentaires ( phonèmes , syllabes, …). Celles-ci sont les unités de base à reconnaître. Cette approche a un caractère plus général que la précédente : pour reconnaître de grands vocabulaires, il suffit d’enregistrer dans la mémoire de la machine les principales caractéristiques des unités de base.
Pour la reconnaissance de mots isolés à grand vocabulaire, la méthode globale ne convient plus car la machine nécessiterait une mémoire et une puissance considérable pour respectivement stocker les images acoustiques de tous les mots du vocabulaire et comparer un mot inconnu à l’ensemble des mots du dictionnaire. Il est de plus impensable de faire dicter à l’utilisateur l’ensemble des mots que l’ordinateur a en mémoire. C’est donc la méthode analytique qui est utilisée : les mots ne sont pas mémorisés dans leur intégralité, mais traités en tant que suite de phonèmes.
* Principe général de la méthode globale pour un système monolocuteur
Le principe est le même que ce soit pour l’approche analytique ou l’approche global, ce qui différencie ces deux méthodes est l’entité à reconnaître : pour la première il s’agit du phonème, pour l’autre du mot.
Dans la structure d’un système de reconnaissance de mots isolés, pour l’utilisation d’un tel système, on peut distinguer deux phases :
– La phase d’apprentissage : un locuteur prononce l’ensemble du vocabulaire, souvent plusieurs fois, de façon à créer en machine le dictionnaire de références acoustiques. Pour l’approche analytique, l’ordinateur demande à l’utilisateur d’énoncer des phrases souvent dépourvues de toute signification, mais qui présentent l’intérêt de comporter des successions de phonèmes bien particuliers. Pour un système multilocuteur, cette phase n’existe pas, c’est la principale différence.
– La phase de reconnaissance : un locuteur (le même que précédemment car nous sommes dans le cas d’un système monolocuteur ) prononce un mot du vocabulaire. Ensuite la reconnaissance du mot est un problème typique de reconnaissance de formes. Tout système de reconnaissance des formes comporte toujours les trois parties suivantes :
o Un capteur permettant d’appréhender le phénomène physique considéré (dans notre cas un microphone),
o Un étage de paramétrisation des formes (par exemple un analyseur spectral),
o Un étage de décision chargé de classer une forme inconnue dans l’une des catégories possibles.
On retrouve ces trois étages dans un système de reconnaissance vocale, comme le montre la figure ci-après :
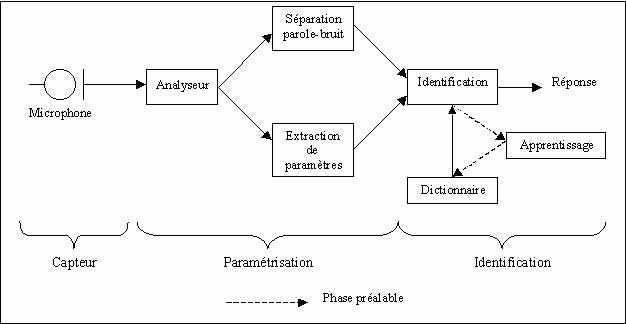
Description des différentes phases de reconnaissance :
1) Le capteur : un signal électrique est issu du microphone lorsque le locuteur parle (cf. détail précédemment).
2) Paramétrisation du signal : cet étage, dont le rôle est d’analyser et de paramétrer le signal vocal du locuteur, consiste en un traitement mathématique du signal. Cette étape vient d’être développée dans la partie précédente. Le signal suite à ce traitement est sous une forme :
– Temps – Fréquence – Intensité
Difficulté rencontrée : comme nous sommes dans le cas de mots isolés, les frontières des mots (début et fin de mot) sont généralement déterminées en repérant les intersections de la courbe d’énergie du signal avec un ou plusieurs seuils évalués expérimentalement. Si la prise de son est effectuée dans un local bruité, le bruit de fond additionné au signal vocal peut dégrader les performances du système de reconnaissance, notamment, en perturbant le fonctionnement de l’algorithme chargé de positionner les frontières des mots.
Dans ce cas, comment séparer le bruit du signal reçu par le microphone afin d’en extraire le signal vocal émis par le locuteur ?
Solution : Une approche couramment utilisée est d’estimer le signal dû au locuteur en soustrayant la densité spectrale du bruit de fond de la densité spectrale du signal mesuré au microphone. Le spectre du bruit de fond étant approximative par la moyenne des spectres de bruit mesurés durant les silences séparant les énoncés. Cette méthode suppose que le bruit de fond est localement stationnaire, c’est à dire que sa densité spectrale mesurée immédiatement avant l’énoncé d’un mot reste identique durant l’énoncé de ce mot.
3) Prise de décision du choix du mot :
Principe : Le signal vocal émis par l’utilisateur, une fois paramétré, va pouvoir être comparé aux mots du dictionnaire de référence (cf. phase d’apprentissage) en terme d’images acoustiques. L’algorithme de reconnaissance permet de choisir le mot le plus ressemblant, par calcul d’un taux de similitude – au sens d’une distance à définir – entre le mot prononcé et les diverses références. Pour simplifier le problème et si l’on prend l’exemple la comparaison de formes par programmation dynamique, le programme va comparer le mot prononcé par le locuteur avec ceux qui sont en mémoire depuis la phase d’apprentissage : dans ce cas la comparaison consiste à soustraire les nuances de gris des pixels du mot prononcé à ceux des mots en mémoire et de répéter cette opération pour chaque ligne et colonne. Ainsi selon le résultat de cette comparaison, on pourra mathématiquement dire quel signal est le plus ressemblant.
Difficulté rencontrée : Ce calcul n’est pas simple, même pour un locuteur unique, car les mots, donc les formes, à comparer ont des durées et des rythmes différents . En effet, un locuteur même entraîné ne peut prononcer plusieurs fois une même séquence vocale avec exactement le même rythme et la même durée. Les échelles temporelles de deux occurrences d’un même mot ne coïncident donc pas, et les formes acoustiques issues de l’étage de paramétrisation ne peuvent être simplement comparé point à point.
Solutions : il existe différentes solutions pour résoudre le problème de l’alignement temporel entre un mot inconnu et une référence :
– Une solution très efficace consiste en un algorithme de comparaison dynamique qui va mettre en correspondance optimale les échelles temporelles des deux mots. On démontre que cette méthode fournit la solution optimale du problème. Elle nécessite, en revanche, beaucoup de calculs. C’est pourquoi pour fonctionner en temps réel, il faut soit réaliser des composants spécialisés de programmation dynamique (plusieurs firmes proposent des systèmes de reconnaissance intégrant un tel processeur), soit simplifier l’algorithme initial.
Les méthodes de comparaison par programmation dynamique ont été largement utilisées pour la reconnaissance de mots isolés. De plus, elles ont été étendues à la reconnaissance de séquences de mots enchaînés sans pause entre eux.
– Il existe cependant d’autres solutions à ce problème de recalage temporel :
o La modélisation stochastique, en particulier sous forme de modèles markoviens Dans cette approche, chaque mot du vocabulaire est représenté par une source de Markov capable d’émettre le signal vocal correspondant au mot. Les paramètres de cette source sous-jacente au processus d’émission d’un mot sont ajustés au cours d’une phase préalable d’apprentissage sur de très gros corpus de parole. La reconnaissance d’un mot inconnu consiste à déterminer la source ayant la probabilité la plus forte d’avoir émis ce mot. (Cf. p68-70 du livre « reconnaissance automatique de la parole » aux éditions DUNOD informatique pour une explication plus détaillée de cette méthode).
o Les modèles neuro-mimétiques qui sont constitués par l’interconnexion d’un très grand nombre de processeurs élémentaires inspirés du fonctionnement du neurone. (Cf. livre » reconnaissance automatique de la parole « )
Avec la méthode analytique, l’ordinateur procède de la même manière que précédemment pour décoder le message parlé (paramétrisation du signal, programmation dynamique, …) sauf que cette fois-ci il s’agit de repérer une suite de phonèmes afin d’associer le mot au mot qui s’y rapporte dans le dictionnaire.
D’autre part, pour identifier un phonème, la machine procède par analyse statistique : elle sélectionne, à partir du dernier phonème identifié, le groupe de phonèmes qui ont la plus forte probabilité de lui succéder immédiatement. Ce premier tri réalisé, l’écart entre le phonème prononcé et chacun des phonèmes retenus est estimé. C’est celui présentant le moins d’écart qui est conservé. Cette analyse statistique est aussi utilisée pour la méthode globale, où elle intervient dans le choix d’un mot en fonction de ce qu’il y a avant (par exemple, on ne peut pas trouver deux verbes conjugués successivement.).
Pour que le taux d’erreur soit aussi faible que possible, les logiciels actuels utilisent également des dictionnaires au vocabulaire spécialisé, choisis selon le type d’activités.
Bilan
En bref, on peut donc dire que le choix de la technique de reconnaissance vocale dépend de l’utilisation :
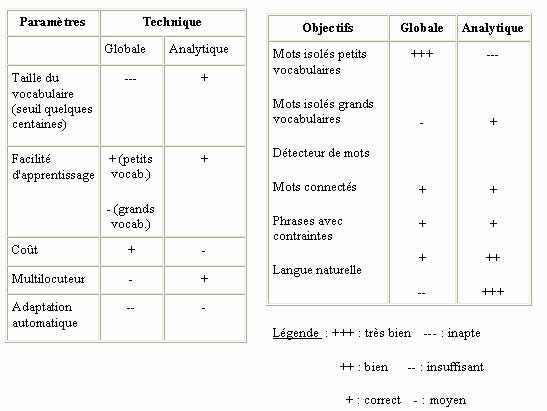
Dans le cas de la reconnaissance de mots isolés (avec un vocabulaire limité), c’est la méthode de reconnaissance globale qui s’applique le mieux . En effet, les images acoustiques des mots peuvent être facilement isolées les unes des autres car tous les mots prononcés sont supposés être séparés par des silences.
Dans cette partie ont été décrit les principes et techniques de base largement utilisés dans les systèmes de reconnaissance par mot. Bien qu’il s’agisse en fait de méthodes très générales qui peuvent être appliquées à la reconnaissance de type phonétique utilisant des unités de décision plus petites que le mot telles que le phonème , cette approche globale est particulièrement adaptée à la reconnaissance de mots isolés (avec un vocabulaire qui ne dépasse pas une centaine de mots) en évitant presque totalement les problèmes de segmentation et de co-articulation. Cependant cette méthode de mots isolés trouve les solutions d’un grand nombre de problèmes comme celui du bruit, ou encore celui de la vitesse d’élocution.
1° Le premier niveau de stratégie : lire ou prédire ?
On distingue deux approches différentes. La première consiste à reconstituer la phrase à partir du signal. Il s’agit là d’une approche ascendante. On » lit » tout simplement le signal. On ne cherche pas à comprendre le résultat obtenu, on se contente de le décrypter. L’inconvénient majeur est qu’il nécessite de tester à chaque portion de phrase l’ensemble des mots contenus dans le vocabulaire. On comprend aisément que dans la parole, le vocabulaire peut très rapidement devenir gigantesque, et cela prend beaucoup de temps machine.
La deuxième approche consiste à prédire le mot à reconnaître. On a ici en opposition une approche descendante. En implantant dans le système une certaine intelligence, la machine pourra prévoir ce qui va être dit. Par exemple, dans un système d’interrogation d’une base de données par téléphone, le premier mot à tester est le mot » allô » ou » bonjour « . Un autre exemple, si la machine reconnaît le mot » monsieur « , le vocabulaire à tester ensuite est celui des noms de personnes contenus dans sa mémoire. Ainsi, cette approche permet de ne pas avoir à tester tout le dictionnaire de la machine, et ainsi à gagner du temps.
On remarquera cependant qu’aucun système ne fonctionne en approche uniquement descendante, et rares sont ceux qui fonctionnent en approche uniquement ascendante. Seuls les systèmes à vocabulaire très restreint peuvent se permettre une approche uniquement ascendante.
2° Le deuxième niveau de stratégie : traitement de gauche à droite ou du milieu vers les cotés ?
A un moment ou à un autre, il faut bien commencer à analyser le signal lui-même. C’est là qu’on doit déterminer la stratégie latérale. Le plus naturel est de procéder par ordre chronologique. C’est ce qu’on appelle le traitement gauche – droite. Il peut cependant s’avérer intéressant d’appliquer le traitement du milieu vers les cotés. Dans cette méthode, on balaye le signal sans une analyse très poussée, on recherche des mots – clés. On accentue la recherche de quelques mots du vocabulaire. Ainsi, après l’application de cette méthode, il est possible d’appliquer une stratégie descendante pour combler les » trous « .
3° Le troisième niveau de stratégie : la recherche d’une solution optimale
On appelle stratégie de recherche l’ensemble des règles qui permettent d’atteindre la solution optimale. On distingue deux grand types de stratégies.
On considère tout d’abord les stratégies totales. Elles consistent en l’examen de toutes les solutions possibles. La machine teste tout son vocabulaire et attribue pour l’ensemble des phrases possibles un score de reconnaissance sous forme de probabilité. Cela est applicable par exemple dans un système de commande par la parole, où le vocabulaire est très limité. Dans un vocabulaire étendu, ceci est évidemment inapplicable.
Les stratégies employées alors sont les stratégies heuristiques. Parmi les stratégies les plus employées, on peut noter celle-ci :
Stratégie du meilleur d’abord : A chaque analyse, le système ne retient que la solution offrant le meilleur score de probabilité. Cette stratégie est très simple à mettre en oeuvre, car elle n’effectue qu’une seule analyse à la fois. On gagne en temps de traitement, mais on perd en performance. Entre cette stratégie et une stratégie totale, il existe cependant un juste milieu.
Recherche en faisceau : On peut la décrire comme étant une stratégie des » quelques meilleurs d’abord « . Elle conserve simultanément les hypothèses les plus plausibles, et poursuit la recherche en parallèle dans les différentes branches. Elle compare enfin les solutions partielles qui vont au même niveau de profondeur dans l’arbre de recherche. Cela est coûteux en temps machine, mais on se rapproche plus d’une solution optimale, car l’espace des solutions explorées est bien plus vaste.
Recherche par îlots de confiance : Dans les stratégies précédentes, une phrase est supposée être analysée de la gauche vers la droite, en partant du début. Ici, on ne recherche que des mots – clés, dont la reconnaissance est quasi – certaine. On obtient donc une phrase à trous, avec ce qu’on appelle des îlots de confiance, dont on est sûr de la reconnaissance. On applique enfin une des stratégies précédentes pour découvrir ce qu’il y a entre.
Les stratégies nécessitent la création d’une mesure de la réussite. Comme dans le cas de la reconnaissance des mots isolés, on retrouve des concepts tels que la probabilité, la similitude, le coût. Ici, il est nécessaire de définir des mesures de la réussite non seulement pour les mots isolés, mais aussi pour les morceaux de phrase reconstitués. C’est ainsi que des systèmes alliant la reconnaissance vocale, mais aussi la compréhension du texte reconstitué offrent la possibilité de définir des scores de réussite très performants. Les meilleurs systèmes actuels utilisent pour définir l’indice de réussite des capacités de compréhension des phrases reconstituées. Ainsi la maîtrise de la syntaxe , de la prosodie ou de la sémantique vont permettre d’accroître les scores de reconnaissance. On touche ici au domaine de l’intelligence artificielle, et la compréhension des phrases reconnues sort du sujet du dossier.
Reconnaissance de la parole continue
Tout d’abord, qu’est ce que la parole continue ? C’est un discours, des phrases où les mots s’enchaînent sans moyen de séparer, contrairement aux mots isolés. Le but de cette partie n’est pas de rentrer dans les détails de la programmation d’un logiciel de reconnaissance de la parole continue, cela serait trop long et fastidieux. On va donc présenter les » ficelles » de la reconnaissance de la parole continue de manière très générale.
Les objectifs de cette partie étant donc éclaircis, on peut entamer la réflexion autour de la reconnaissance de la parole continue. Pourquoi, après tout, s’évertuer à attribuer à une machine de telles capacités ? Est-ce par pure fantaisie que les auteurs de science-fiction inventent des dialogues entre un héros et sa machine ? Non, ceci relève dun besoin qui pourrait se résumer à une chose : la recherche dun confort et damélioration de linteraction de lhomme avec la machine. Les avantages dun tel progrès sont simples à imaginer.
Cette partie du dossier va donc s’attacher à comprendre les mécanismes mis en jeu dans la reconnaissance de la parole continue, et plus précisément, les stratégies à mettre en oeuvre pour aboutir à un bon résultat. Nous avons pu voir dans la partie précédente, intitulée » reconnaissance de mots isolés « , les méthodes pour reconnaître un mot. Dans une phrase, les mots s’enchaînent sans aucun moyen apparent de les dissocier. C’est là qu’intervient la notion de stratégie. La problématique à résoudre est comment découper un signal afin de reconnaître les différents mots ou phonèmes qui le compose.
Dans cette partie, on ne se propose pas de faire une liste exhaustive des applications, mais d’en citer quelques-unes qui nous ont parus intéressantes dans chaque » domaine « , puis de montrer les évolutions du marché pour permettre de se rendre compte de l’importance de la reconnaissance vocale aujourd’hui.
Quelques applications
De façon générale, le choix d’une application doit faire l’objet d’une étude attentive, fondée sur un ensemble de critères objectifs. En particulier, il est important d’examiner si la voix apporte véritablement un accroissement des performances ou un meilleur confort d’utilisation. Par ailleurs, il ne faut pas trop attendre de la commande vocale mais la considérer, en tout état de cause, comme un moyen complémentaire parmi d’autres moyens d’interaction homme-machine plus traditionnels.
Bien entendu, à chaque type d’application correspondent des critères de performance différents. Ainsi, pour des applications en reconnaissance de la parole, on jugera la qualité d’une application sur les quatre critères principaux suivants :
– le débit du flux de parole correctement reconnu. Si le locuteur prononce les mots séparément avec de petites pauses (environ 200 ms) entre chaque mot, on parlera de reconnaissance par mots isolés, sinon ce sera de la reconnaissance de parole continue.
– la taille du vocabulaire correctement reconnu. Ce vocabulaire variera de quelques mots (la cabine téléphonique à entrée vocale) à plusieurs milliers de mots (la machine à écrire à entrée vocale).
– les contraintes imposées par le système sur l’environnement de fonctionnement : acceptation de bruits de fond et parasites divers. Des critères de qualité positifs dans certaines applications peuvent être négatifs dans d’autres : l’indifférence au locuteur est recherchée pour une cabine téléphonique à numérotation vocale alors qu’au contraire c’est la capacité de discrimination entre locuteurs qui déterminera la qualité d’une serrure à commande vocale.
– les contraintes imposées par le système sur l’utilisateur : est-il unique ou multiple, doit-il s’astreindre à une phase d’apprentissage préalable ?
Reconnaissance de petits vocabulaires de mots isolés
La reconnaissance de mots isolés, le plus souvent monolocuteur , pour des vocabulaires de quelques dizaines jusqu’à quelques centaines de mots est un problème assez bien résolu. Les premiers systèmes commerciaux de cette catégorie sont apparus il y a un peu plus de vingt ans. D’importants progrès ont été réalisés sur la reconnaissance de petits vocabulaires de mots isolés, multilocuteur , dans des conditions difficiles (par exemple la reconnaissance de chiffres à travers le réseau téléphonique ).
L’avionique et l’automobile
L’avionique est un domaine d’application important des commandes vocales. Des systèmes de reconnaissance par mots ont été utilisés avec succès dans des avions de chasse pour permettre au pilote déjà suroccupé de commander diverses fonctions ( radio, radar,…), notamment aux Etats-Unis, en France (Sextant Avionique), et en Grande Bretagne. La voix a également servi au contrôle d’un bras articulé lors de la mission de la navette spatiale américaine.
En effet, à bord d’avion comme à bord d’automobile, les tâches étant complexes et le tableau de bord réduit, la parole permet au pilote ou au conducteur d’avoir à sa disposition un moyen supplémentaire d’interaction avec la machine, sans cependant gêner l’accomplissement des tâches courantes qui requièrent de sa part toute son attention visuelle. En voiture, les infrastructures nouvelles de communication par satellite (projets IRIDIUM et GlobalStar) pour la transmission à haut débit d’images et de sons, la norme européenne de téléphone mobile GSM, et le système GPS (Global Positioning Satellite System) qui permet de connaître le positionnement du véhicule, offrent au conducteur une connaissance dynamique de l’évolution de la circulation et de la météorologie, et lui permet non seulement d’établir la planification de son itinéraire et d’être guidé par des messages vocaux, mais encore d’accéder à tout moment à des bases de données touristiques et à des services variés.
Dans le domaine de l’avionique les études menées dans ce domaine par Sextant Avionique en France (système TOP-VOICE) [Pastor,1993], par Marconi et Smith Industries en Angleterre, en Allemagne (système CASSY, [Gerlach, 1993]) visent à rendre les systèmes de reconnaissance plus robustes aux bruits (moteur d’avion, masque à oxygène, etc.).
En ce qui concerne l’aide à la navigation à bord de voiture, ces systèmes s’appuient sur la mise en place de réseaux de radiodiffusion RDS-TMC (Radio Data System Traffic Message Channel) et font l’objet de plusieurs projets nationaux et européens. Le produit CARIN [Cardeilhac, 1995], développé par Philips et Lernout & Hauspie devrait s’adresser à terme aussi bien à des professionnels (routiers) qu’au grand public. La synthèse de haute qualité multilingue [Van Coile, 1997] (français, anglais, allemand et hollandais) permet de dispenser à bord du véhicule des informations dans la langue du conducteur, quel que soit le pays traversé. Un service régulier de diffusion TMC pour la langue allemande en Allemagne a été mis en place en 1997 et devrait être étendu à d’autres pays et d’autres langues bientôt. Le système utilise de la synthèse à partir du texte pour la diffusion des messages, afin de garantir un encombrement mémoire réduit et une certaine flexibilité pour toute modification ultérieure.
On peut citer plusieurs autres projets : le projet CARMINAT avec comme partenaires Renault, Peugeot, Philips, TDF et Sagem ; en Italie, le système Route Planner de Tecmobility Magneti Marelli [Pallme, 1995] ; en Angleterre le système d’interrogation des informations diffusées par le satellite Inmersat-C, étudié par Marconi [Abbott, 1993]… Dans la plupart des cas, il est prévu d’adjoindre au système une interrogation vocale (système AudioNav de reconnaissance de courtes phrases et mots-clés développé par Lernout & Hauspie en Belgique intégré dans le projet VODIS auquel participent Renault et PSA.
Télécommunications
L’apparition récente de systèmes multilocuteurs présentant de bonnes performances à travers le réseau téléphonique commuté ( jusqu’à 99% de reconnaissance pour de petits vocabulaires ) ouvre de nouveaux champs d’applications : serveurs d’informations, réservations, autorisations bancaires. De tels systèmes sont par exemple commercialisés par Voice Processing, Scott Instruments,… Des tests en vraie grandeur ont été menés avec succès avec le grand public, en particulier en France et au Canada. Dans le secteur de la téléphonie, les grandes sociétés de télécommunication ont engagé une course à l’innovation. Ainsi, il suffit de dire le nom du correspondant désiré dans le récepteur, à condition de l’avoir préalablement encodé, pour obtenir la communication souhaitée. Ceci peut-être très utile pour téléphoner depuis une voiture.
L’information au public est aussi un domaine concerné par la numérisation de la parole. Dans les gares ou les aéroports, par exemple, on pourra bientôt voir des bornes interactives qui remplaceront les agents préposés aux renseignements. Pour connaître l’horaire d’un train, il suffira de demander de vive voix à la machine où on veut aller et quand, et elle répondra dans la langue de notre choix, avant de nous souhaiter un agréable voyage.
Plus précisément, aujourd’hui, deux gammes de services dominent le marché des services de Télécommunication à commande vocale : ce sont les services à opérateurs partiellement automatisés et les services de répertoires vocaux, évoluant progressivement vers des services plus complets d’assistants téléphoniques.
L’automatisation des services à opérateurs (assistance aux opérateurs)
Ces services représentaient en 1997 environ 25% du marché, mais leur part devrait décroître dans les prochaines années, du fait de leur saturation et de l’augmentation beaucoup plus forte des autres gammes. L’intérêt de ces services est d’ordre économique. Quand un utilisateur appelle un service à opérateur, toute seconde de conversation avec l’opérateur qui peut être gagnée par un dialogue automatisé avec un serveur vocal se traduit par des gains d’exploitation très importants. Parmi les nombreux enseignements apportés par ces premiers services grand public de grande ampleur (plusieurs millions d’appels par jour), le besoin de systèmes très robustes a été mis clairement en évidence (Nortel utilise 200 modèles différents pour reconnaître les mots » oui » et » non » et leurs synonymes en deux langues), ainsi que la nécessité d’éducation et de communication autour de la commande vocale auprès du grand public, et la nécessité d’enrichir progressivement les modèles utilisés par des données d’exploitation réelle.
Les répertoires vocaux
Cette gamme de services représente aujourd’hui, au niveau mondial, environ 50% du marché des services à commande vocale. Ici, la reconnaissance vocale sert à associer un numéro de téléphone au nom du correspondant désigné, offrant ainsi un naturel et une rapidité de numérotation accrus par rapport au clavier. Cette gamme de services est principalement justifiée dans l’environnement mobile (mains occupés, yeux occupés) où la numérotation par clavier est peu commode, voire dangereuse. Le service est souvent couplé, pour les mobiles, à un service de numérotation vocale (de plus en plus souvent en parole continue), permettant d’établir tout appel sans intervention manuelle.
Katalavox
Le système de reconnaissance vocale Katalavox (cf bibliographie pour plus de renseignements) est utilisé dans plusieurs pays à travers le monde et a les caractéristiques suivantes :
– C’est un système monolocuteur.
– Il reconnaît des mots isolés (ou expressions jusqu’à 1,5 secondes).
– Il fonctionne dans des environnements bruyants.
Il est utilisé en micro-chirurgie, pour contrôler les mouvements du microscope opératoire par des ordres à la voix au lieu d’utiliser des pédales. La première opération l’utilisant a été faite en 1984 par le Prof. Dr. Aron-Rosa à l’hôpital de la fondation Rothschild à Paris. Toutes les fonctions de son microscope : le focus, le zoom et les mouvements en X-Y étaient contrôlés à la voix.
Aujourd’hui, le Katalavox est utilisé par des chirurgiens dans plusieurs pays. Il peut également contrôler des opérations auxiliaires telles que le contrôle d’un magnétoscope, d’un appareil photo, de l’éclairage de la salle d’opération,…
Le Katalavox est aussi utilisé par des personnes tétraplégiques, pour contrôler à la voix le fauteuil roulant électrique. Un micro laryngophone capte les vibrations des cordes vocales quand l’utilisateur prononce un mot de commande. Ceci l’isole du bruit bruyant. Dans certains cas, un autre type de microphone peut également être utilisé. Le premier fauteuil à commandes vocales fût utilisé par un norvégien en 1984. Le système de reconnaissance vocale s’adapte à n’importe quel langue. Même si quelqu’un a des difficultés de prononciation, le système est capable de reconnaître des sons distincts. Il suffit de cinq sons pour contrôler un fauteuil. Les mots de commande sont combinés pour permettre d’émuler les mouvements d’un joystick. Le Katalavox peut aussi être utilisé par des personnes tétraplégiques pour contrôler leur environnement. Il leur permet d’allumer et éteindre des lampes et autres appareils dans leur maison, de contrôler la télévision et des appareils à télécommande infra-rouge, et de répondre au téléphone et composer des numéros de téléphone. Le système de contrôle d’environnement peut également être inclus dans la commande d’un fauteuil roulant à commandes vocales. Ce créneau d’application devrait se développer à l’avenir avec la diminution du coût des systèmes.
Cette commande vocale est utilisée dans l’automobile depuis 1984 pour les conducteurs phocoméliques ou n’ayant pas l’usage des bras. Une direction au pied gauche remplace le volant, l’accélérateur et le frein sont actionnés par le pied droit. Les fonctions secondaires, telles que les clignotants, l’essuie-glace, le lave-glace, l’avertisseur, l’éclairage,… sont contrôlées à la voix. En janvier 1984 le premier permis de conduire portant la mention : » fonctions secondaires contrôlées par commande vocale » a été remis à une personne handicapée dont le véhicule était équipé d’un Katalavox.
Reconnaissance de grands vocabulaires
Microsoft, en passant par Apple et IBM, de nombreux industriels travaillent sur des projets de reconnaissance vocale, généralement en complément d’une activité de recherche sur la synthèse de la parole, le tout s’insérant dans des projets plus généraux d’interface homme-machine.
Il faudra attendre encore plus longtemps avant que la machine remplace purement et simplement la secrétaire dactylo pour la saisie de textes sur ordinateur. Les systèmes de reconnaissance vocale actuels sont encore bien trop grossiers pour comprendre toutes les finesses qui peuvent se glisser dans la syntaxe et dans les intonations de la langue parlée en continu et non plus sous la forme de mots clés ou de petites phrases sommaires.
Dictée personnelle d’IBM.
Un des produits les plus avancés est le système de dictée personnelle d’IBM. La cadence est de 70 à 100 mots par minute et le taux de reconnaissance approche 97%. Des dictionnaires volumineux et spécialisés facilitent le processus de reconnaissance et limitent les interventions de l’utilisateur pour préciser l’orthographe d’un mot. Ceci est le résultat de vingt ans de recherche acharnée, conjugués aux efforts de centaines d’ingénieurs mobilisés pour un budget qui n’a pas été dévoilé.
Pour utiliser le logiciel, il faut une heure et demie d’apprentissage consacrée à lire quelque cent soixante phrases pour que le système reconnaisse la voix. Il faut aussi un peu de self-control car il faut faire l’effort d’une diction » saucisson » et omettre de faire les liaisons entre les mots. Cela permet au logiciel d’analyser le spectre de la voix, tout comme les défauts de prononciation et d’élocution : cheveu sur la langue, élision de certains phonèmes , accents régionaux… C’est pourquoi le système est monolocuteur, c’est-à-dire qu’il ne reconnaît qu’un seul orateur à la fois.
Le français, riche en homophones ( sang et sans ), est l’une des langues en gras.
– On peut automatiser l’écriture de phrases que l’on utilise fréquemment, une formule de politesse par exemple, en déclenchant leur rédaction par la simple énonciation d’un mot clé.
– Pour indiquer la prononciation, il suffit de la dicter par des ordres naturels comme » point à la ligne « .
– On peut dicter directement avec son propre traitement de texte, sa messagerie Internet, son logiciel de gestion.
– Il est possible d’enregistrer plusieurs utilisateurs sur un même poste de travail.
– Pour pouvoir utiliser ce logiciel, il faut un ordinateur multimédia, Windows 95/98 ou NT 4, un processeur Pentium 133, une mémoire vive de 32 Mo sous Windows 95/98, 48 Mo sous Windows NT, il faut ajouter 16 Mo pour l’intégration dans Word 97 et la synthèse vocale.
L’occupation sur le disque est de 87 Mo.
Pour avoir un ordre d’idée, le Dragon Naturally Speaking standard coûte 790 Francs TTC, le Dragon Naturally Speaking Professional coûte 4990 Francs TTC.
Les systèmes présentés par IBM, Kuzweil et Dragon Systems sont le plus souvent fondés sur une modélisation stochastique de la parole, méthode actuellement la plus performante (1992).
L’avenir est aux systèmes continus et à l’indépendance vis à vis du locuteur, sans phase d’apprentissage. Ces caractéristiques demeurent difficiles à mettre en œuvre sur ordinateur, que ce soit en raison de l’absence d’algorithmes linguistiques sophistiqués ou, plus logiquement, parce que les processeurs sont encore trop peu puissants. Les recherches sur le traitement du langage naturel et sur le traitement du signal (notamment NSP-Native Signal Processing chez Intel et Microsoft ) aboutiront très certainement à des solutions complètement logicielles, qui s’intègreront aux systèmes d’exploitation. On sait déjà que les prochaines versions de Windows proposeront des fonctions de synthèse et de reconnaissance de la parole. (1996)
Les données sur ces systèmes évoluant très rapidement, nous avons joint en annexe 1 et 2 les données récentes trouvées sur Internet, comme notamment leur prix actuels.
En conclusion, les technologies vocales ont de fait déjà pénétré des domaines d’activité de la vie courante (serveurs interactifs vocaux, aide à la navigation à bord de voiture et aide à la formation).
Outre ces domaines en expansion, la dictée automatique de documents écrits, notamment de rapports médicaux, semble constituer un domaine particulièrement prometteur du fait de systèmes pouvant traiter un nombre croissant de langues. L’expansion de ces nouveaux modes de communication ne deviendra cependant effective que si les performances des systèmes atteignent un niveau acceptable pour le grand public, en termes de fiabilité mais aussi de facilité d’utilisation. L’effort entrepris par la communauté scientifique pour se doter d’outils linguistiques adaptés à une meilleure évaluation des systèmes constitue une première étape. Des études socio-économiques pour identifier les besoins réels des utilisateurs doivent conduire à une plus large concertation pour convenablement intégrer les technologies vocales dans des applications réalistes.
Le marché
Les données que nous allons présenter sur le marché datent de 1991 et sont tirées de » Langage humain et machine « .
Bien que depuis 1985 les études traitant des applications dans le domaine des industries de la langue soient relativement nombreuses, peu d’entre elles fournissent des éléments financiers sur les marchés potentiels, les marchés réels ou les marchés futurs. Les difficultés d’évaluation sont en effet considérables et tiennent à plusieurs raisons. En effet, à quelques exceptions près, aucun des principaux fournisseurs dans le domaine n’a pour unique activité le traitement automatique des langues naturelles, et les applications développées sont souvent très spécifiques, ce qui rend difficile la collecte des informations et les évaluations des coûts. Dans certains cas, les détenteurs des informations ne souhaitent d’ailleurs pas les voir publier. Ainsi, les entreprises de service en traduction qui utilisent des systèmes de traduction assistée par ordinateur ( TAO ) pour réaliser une partie de leur chiffre d’affaire ne donnent généralement pas d’éléments qui permettraient des évaluations précises. En effet, celles qui réussissent à obtenir des améliorations sensibles de productivité, alors qu’elles facturent au prix de la traduction humaine, ne veulent pas voir leurs clients demander des rabais. Une autre difficulté résulte de ce que certains secteurs du marché des industries de la langue sont fortement influencés par des acteurs qui fonctionnent avec des logiques non commerciales.
Ainsi le secteur de la traduction assistée par ordinateur est largement dépendant de décisions politiques ou stratégiques. Ainsi, par exemple, le nombre réel de pages transitant par le système de TAO utilisé en interne par la Commission des communautés européennes ( de l’ordre de 5000 pages pour toute l’année 1990 ) est rarement affiché sur la place publique tant il est faible par rapport aux sommes dépensées en recherche et développement par cet organisme depuis une quinzaine d’années. Entre 1975 et fin 1990, ces investissements ont été d’environ 126,5 millions de francs. Si l’on prend le montant des subventions publiques directes ou indirectes versées aux entreprises, le chiffre d’affaire de la TAO dans le monde paraît relativement important. Si, par contre, on évalue le chiffre d’affaire d’après le nombre de pages effectivement traduites, le résultat est bien différent. Le domaine de la TAO présente depuis sa création le paradoxe des secteurs où la technologie n’est pas maîtrisée : le chiffre d’affaire potentiel est énorme et les clients potentiels relèvent essentiellement du secteur privé, cependant le marché réel est faible et les payeurs réels principaux sont des services publics.
Les grandes fonctions linguistiques ( traduire, parler, écouter, corriger, lire,…) ne peuvent être totalement automatisées et donc, l’introduction des machines ne se fait que dans des environnements locaux favorables.
Les difficultés rencontrées dans la mesure des marchés réels et potentiels, comme dans la mise au point des projections se traduisent par des évolutions continuelles dans les prévisions. Evidemment, celles-ci s’affinent au fur et à mesure que le domaine est mieux cerné, qu’il se développe et que sont installés des indicateurs plus fiables.
A titre d’exemple, on a présenté ci-après, pour la reconnaissance de la parole, une série de quatre courbes (figure 14) qui met en évidence l’évolution dans le temps des perspectives de marchés. Dans les prévisions successives, on voit clairement apparaître un phénomène de surestimation initiale de la croissance du marché, qui s’estompe progressivement. Ce phénomène n’est pas particulier au traitement de la parole. Il s’est également produit en traduction assistée par ordinateur, domaine où, malgré tout, on note de meilleures concordances des prévisions formulées en 1983, puis en 1986 avec la réalité aujourd’hui constatée.
Il y a d’une part des activités Bureautique en quête d’améliorations de productivité, d’autre part des industries de l’information en expansion rapide, et enfin, des industries électroniques et informatiques qui profitent largement des deux phénomènes précédents, puisqu’elles fournissent les équipements. Les développements en matière de traitement automatique des langues naturelles s’inscrivent donc dans des logiques puissantes, qui expliquent le taux de croissance particulièrement rapide du domaine.
Si imprécises soient-elles, pour les raisons que nous avons évoquées plus haut, les précisions d’évolution des marchés sur le domaine des industries de la langue donnent cependant des ordres de grandeur intéressants. En voici quelques-unes, parues entre 1985 et 1990 dans la presse spécialisée :
– Presse, édition, bureautique intelligente (traitement de textes, assistance à la saisie et à la correction de textes, aides à la rédaction) : de 4,5 millions de dollars (M$) en 1985 à 50 M$ en 1990 (en France).
– Indexation et gestion de fonds documentaires : de 125 M$ en 1985 à 400 M$ en 1990 (en Europe).
– Traduction assistée (notices techniques de produits industriels) : de 4,5 M$ en 1985 à 10 M$ en 1990 (en Europe).
– Interfaces homme-machine (reconnaissance et synthèse vocale, accès à l’information en langage quasi-naturel.).
o Communication parlée : de 30,5 M$ en 1985 à 250 M$ en 1990 (monde).
o Interfaces clavier-écran : de 18,7 M$ en 1985 à 54 M$ en 1990 (aux États-Unis).
En 1990, on estime généralement que le marché total des industries de la langue en France se place dans une fourchette de 300 à 350 millions de francs (source : ministère de la Recherche et de la Technologie) dont 80 à 100 millions de francs pour le traitement de la parole. Ce marché est encore très étroit : 350 millions de francs, soit à peu près le chiffre d’affaire d’une société de service en informatique de 350 salariés, ou encore celui d’une entreprise moyenne de distribution de micro-ordinateurs et de logiciels de bureautique. Cette étroitesse se confirme lorsque l’on évalue des sous-domaines. Ainsi, le marché total de la traduction humaine (vente par des entreprises spécialisées, traducteurs individuels et traductions internes) en France est estimé à environ 1,2 milliard de francs (source Bossard Consultants). Dans l’hypothèse optimiste où 1% de ce marché serait partiellement ou totalement automatisé, on obtient un chiffre d’activité pour le service en TAO d’environ 12 millions de francs. Ainsi donc, bien qu’on en parle beaucoup, la traduction assistée par ordinateur ne représente qu’une part infime de l’activité du domaine. De fait, il semble qu’exprimé en chiffre d’affaire, le principal domaine d’application des industries de la langue soit actuellement l’interrogation de bases de données et de systèmes documentaires.
Le taux de croissance du chiffre d’affaire des entreprises qui travaillent sur l’écrit, observé sur les trois dernières années, varie de 20% à 50% avec une moyenne à 35% (source : ministère de la Recherche et de la Technologie). Ce taux est comparable à celui qui est observé dans le domaine du traitement de la parole. Pour 1990, en Europe, le marché du traitement de la parole serait de l’ordre de 700 millions de francs, avec une actuelle domination du Royaume-Uni (44%) progressivement remplacée par une domination allemande (33% en 1994 pour un marché total de 4 milliards de francs) (source : Frost et Sullivan).
Voici quelques données plus récentes tirées de » La parole, des modèles cognitifs aux machines communicantes « (1998). Le marché de la commande vocale s’élève en 1997 à 400M$, à 80 M$ pour la synthèse à partir du texte et 10 M$ pour l’authentification vocale, avec des taux de progression annuels respectifs, mesurés en 1997, de 100%, 300% et 30% (source : W.S. Meisel, 1998 : » The telephony voice user interface, applications of speech recognition, text-to-speech, and speaker verification over the telephone « ,TMA Associates, Tarzana, CA, USA). Ces chiffres sont à comparer au marché des services téléphoniques (qui exploitent donc la seule compression de parole) qui s’élève à plusieurs dizaines de milliards de francs, pour la France.
Conclusion ? NON !
Tant qu’un Inventeur existera ; tant que l’activité de l’œuvre et de l’esprit continuera à hanter Madame et Monsieur tout le monde, on est loin de conclure.
La reconnaissance vocale est un procédé assez récent puisqu’il est apparu dans les années 50 et qui nécessite encore des améliorations. En multilocuteur, les performances actuelles, qui dépendent fortement du locuteur, se situent autour de 70 % de reconnaissance et on estime qu’il faut au moins 85 % pour comprendre ensuite ce qui a été dit. Cependant, les chercheurs prennent désormais en compte les données linguistiques en plus de données acoustiques, ce qui devrait permettre de progresser fortement.
Quant aux applications, il y a fort à parier que nous les retrouverons partout dans la vie de tous les jours d’ici quelques années. Elles apparaissent déjà dans des domaines aussi variés que l’automobile, les portables ou les avions. De plus, la reconnaissance vocale associée à la synthèse vocale pourrait par exemple permettre de réaliser un système capable de comprendre ce que dit une personne dans une langue puis de le traduire oralement dans une autre, ce qui rendrait possible une discussion entre deux personnes ne parlant pas la même langue. Tout cela risque de révolutionner la manière dont on interagit avec notre environnement.
Cependant, même dans le futur, la reconnaissance vocale risque d’atteindre rapidement des limites. En effet, nous avons parfois du mal à comprendre ce que dit une personne en raison par exemple de mots homophones. On peut donc se demander comment une machine, dont le principe de reconnaissance est fondé sur celui de l’homme, serait capable de faire mieux.
Actuellement, on obtient des systèmes qui fonctionnent très bien. Mais autant aux balbutiements de la reconnaissance vocale, on n’utilisait qu’une stratégie principale, que maintenant, ce sont des combinaisons de toutes qui offrent les meilleurs résultats.
On peut noter cependant qu’aucun système n’a su obtenir un fonctionnement optimal. On est capable de construire une machine monolocuteur en temps réel, qui fonctionnerait avec des stratégies descendantes et heuristiques . On est aussi capable de construire des machines multilocuteurs, qui se tournent plus vers des stratégie totales, mais auxquelles il faut laisser la nuit pour réfléchir.
A CŒUR VAILLANT RIEN D’IMPOSSIBLE
Il est permis de dire que même le Superordinateur le plus puissant n’a pas la capacité de raisonnement démontrée par un enfant absorbé par un livre de Caillou. Les ordinateurs ne peuvent lire comme nous le faisons. Ils ne peuvent en fait ni lire ou apprendre comme nous. Et quand bien-même on ajoutera à un ordinateur des capteurs et lecteurs optiques de manière à le robotiser en input-output ; réduire l’écart cognitif existant entre l’homme et la machine, c’est créer quasiment un ordinateur qui peut lire et apprendre à un niveau sophistiqué.
C’est un objectif d’importance pour les chercheurs en intelligence artificielle.
La Defense Advanced Research Project Agency du Pentagone, ou DARPA, a accordé un contrat d’une valeur d’au moins 400 000$ US l’automne dernier à deux professeurs de l’Institut polytechnique Renfaîter qui tentent de concevoir une machine qui pourra apprendre par le biais de la lecture.
Les chercheurs espèrent créer une machine qui peut lire des sections d’ouvrages et répondre ensuite à des questions portant sur le matériel parcouru. Le professeur Selmer Bringsjord est d’avis que de telles machines à l’intelligence artificielle pourraient lire des plans ou des manuels militaires et prendre des décisions spontanées dans le feu de l’action.
«Le domaine militaire est si complexe de nos jours, la technologie si évoluée que nous avons besoin du secours de l’intelligence artificielle,» affirme Bringsjord, directeur du laboratoire d’intelligence et de raisonnement artificiels de RPI. «Nous avons atteint un point de non-retour.»
Cela peut sembler sortir tout droit de la science-fiction, mais c’est à peine exagéré. Les machines sont déjà cognitives, selon votre définition du mot.
Austin, Texas, Cycorp Inc. travaille à l’élaboration d’une base de connaissances appelée «Cyc», avec l’objectif d’en faire un dépôt d’archives de connaissances humaines qui peuvent mener à des prises de décisions intelligentes.
Les machines pouvant comprendre la parole, reconnaître des visages et faire des inférences basées sur l’expérience existent déjà, dit Tom Mitchell, professeur de sciences informatiques à l’université Carnegie Mellon. Mitchell, qui a déjà été président de l’Association américaine de l’intelligence artificielle, sert un avertissement : même si les chercheurs ont fait d’immenses progrès dans différents domaines de la cognition, un nuage de mystère subsiste toujours sur la façon d’assembler toutes les pièces du casse-tête.
Inventeurs à vos marques ! il le faut c’est une nécessité pour sortir de l’isola..
Auteur : Mathias WOU
En savoir plus sur Invention - Europe
Abonnez-vous pour recevoir les derniers articles par e-mail.
